TL;DR: Tokens aren't words — they're subword chunks averaging 4 characters each. A typical 1,000-word English prompt uses about 750 tokens. But system prompts, JSON formatting, and accumulated chat history can silently inflate your token count by 2-5x. Count before you send, not after you're billed.
Every dollar you spend on LLM APIs comes down to one number: tokens. Not words. Not characters. Tokens. And if you don't understand the difference, you're going to overpay.
Try our free LLM Token Counter to see exactly how many tokens your prompts use before you send them to any provider.
What exactly is an LLM token?
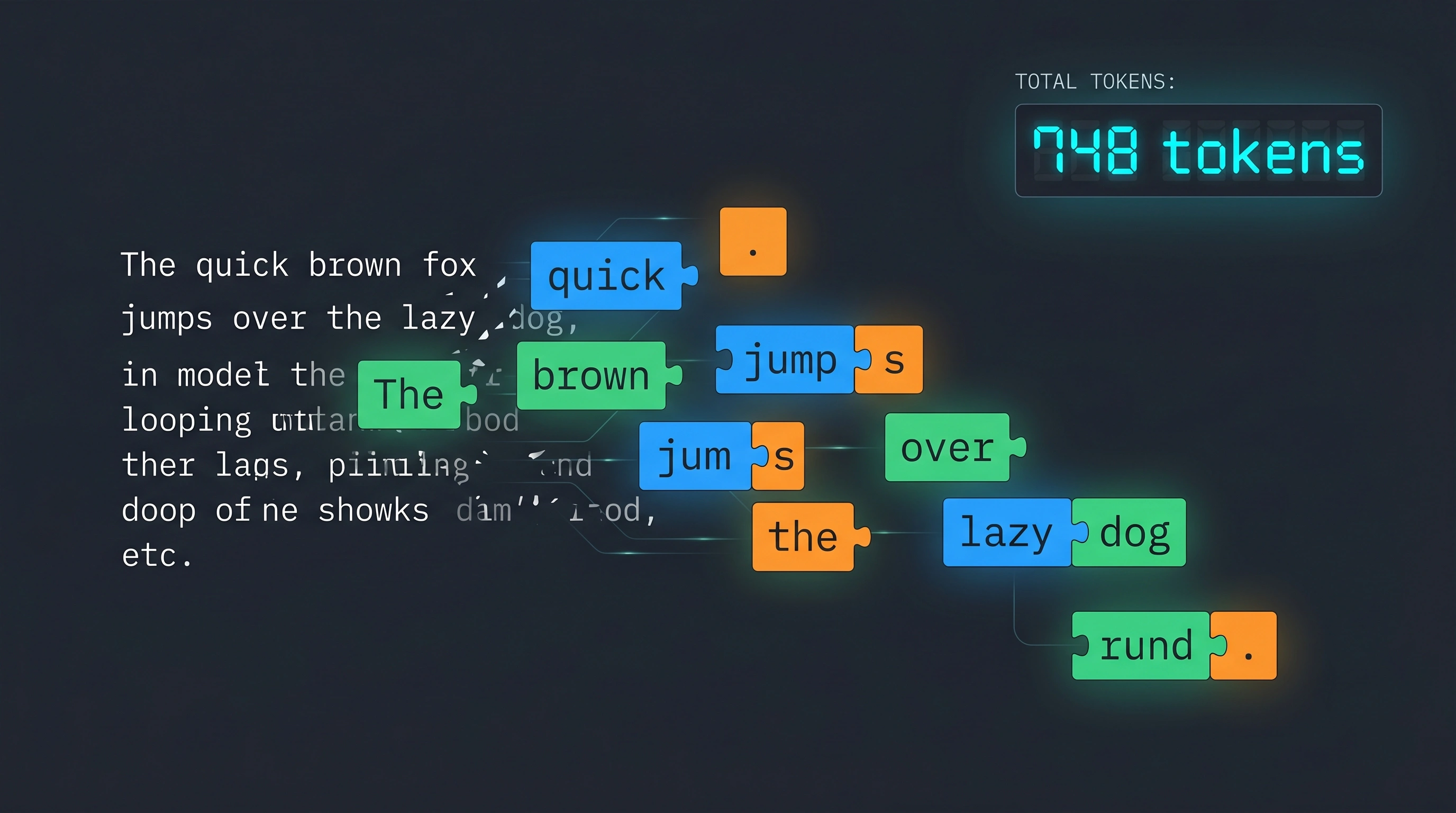
A token is a subword unit — a chunk of text that the model treats as a single piece. Sometimes it's a full word. Sometimes it's part of a word. Sometimes it's just a space or a punctuation mark.
The word "tokenization" gets split into something like ["token", "ization"] — two tokens for one word. Meanwhile, common words like "the" or "is" are single tokens. Numbers get weird: "2026" might be one token, but "178105185128" could be four or five.
This matters because every LLM provider bills by tokens, not by words or characters. OpenAI charges per million input and output tokens. Anthropic does the same. Google, DeepSeek, xAI — all tokens.
How does tokenization actually work?
Most modern LLMs use a method called Byte Pair Encoding (BPE). Here's the simple version: the algorithm starts with individual characters and repeatedly merges the most common pairs until it builds a vocabulary of subword units — typically 50,000 to 100,000 tokens.
GPT-4o uses a tokenizer called o200k_base with about 200,000 tokens in its vocabulary. Claude uses its own BPE variant. The bigger the vocabulary, the more efficiently common phrases get compressed into fewer tokens.
The practical result: English text averages roughly 4 characters per token. One word is about 1.3 tokens. And 1,000 words of typical English prose produce approximately 750 tokens.
But those are averages. Code tends to tokenize less efficiently — Python might run 1.5 tokens per word because of indentation and special characters. JSON is even worse, with all those curly braces and quotation marks eating tokens.
Why do different models tokenize the same text differently?
Each model family uses its own tokenizer. That means the exact same prompt can produce different token counts depending on where you send it.
GPT-4o and GPT-4o-mini share the same tokenizer, so their counts match. But send that same text to Claude, and you'll get a slightly different number. Google's Gemini models use yet another tokenizer based on SentencePiece.
In practice, the differences are small for English text — usually within 5-10% of each other. But they add up. If you're running 100,000 API calls per day, a 10% difference in tokenization efficiency means a 10% difference in your bill.
This is why you should estimate your costs with the specific model you plan to use, not just a generic "words to tokens" ratio.
How many tokens does a typical API call use?
Here's where most teams get surprised. They count the tokens in their user prompt and think that's the total. It's not even close.
A typical chat completion request includes:
- System prompt: 200-500 tokens for instructions, persona, and guardrails
- Chat history: Every previous message in the conversation, growing with each turn
- User message: The actual new input — often the smallest part
- Function/tool definitions: 100-300 tokens per tool if you're using function calling
- Output tokens: The model's response, which you also pay for
A "simple" chatbot with a 300-token system prompt, 5 turns of history averaging 150 tokens each, and a 50-token user message is already at 1,100 input tokens before the model generates a single word of output.
After 20 turns of conversation, that same chatbot might be sending 4,000+ input tokens per request. Your cost per response has quietly quadrupled.
What are the biggest token count gotchas?
System prompts count every single time. Your 400-token system prompt gets sent with every request in a conversation. Ten messages means you've paid for that system prompt ten times. This is why prompt caching exists — OpenAI and Anthropic both offer discounts on repeated prefixes.
JSON is token-hungry. Curly braces, quotation marks, colons, commas — they all consume tokens. A JSON object with 10 key-value pairs might use 2x more tokens than the same data as plain text. If you're passing structured data, consider whether you actually need full JSON formatting.
Whitespace adds up. Extra spaces, blank lines, and indentation all get tokenized. A neatly formatted prompt with generous spacing might use 15-20% more tokens than a compact version. This is one reason prompt optimization can save real money.
Chat history accumulates fast. Without a strategy for managing context windows, multi-turn conversations balloon in cost. After 10 turns, you might be sending 10x the tokens of your first message. Summarizing older turns or using sliding windows can cut costs significantly.
How can you count tokens before sending a request?
You've got several options, from quick estimates to exact counts.
Quick math: Divide your word count by 1.33. A 1,000-word prompt is roughly 750 tokens. This gets you within 10-15% for English prose.
Online tools: Use our LLM Token Counter to paste your prompt and get an exact count for multiple models simultaneously. You'll see exactly how GPT-4o, Claude, and Gemini tokenize the same text differently.
Programmatic counting: OpenAI's tiktoken library (Python) gives exact counts for GPT models. Anthropic's API returns token counts in response headers. Google provides a countTokens endpoint.
import tiktoken
encoder = tiktoken.encoding_for_model("gpt-4o")
tokens = encoder.encode("Your prompt text here")
print(f"Token count: {len(tokens)}")
API-side tracking: If you're running production workloads, you need automated tracking. Every API response includes token counts in the usage object. Tools like Tokonomics record these automatically and show you exactly where your budget goes.
How do you estimate costs from token counts?
Once you know your token count, multiply by the provider's per-token rate. But remember: input and output tokens have different prices.
GPT-4o charges $2.50 per million input tokens and $10.00 per million output tokens. Claude Sonnet 4 is $3.00 input and $15.00 output. GPT-4o-mini is dramatically cheaper at $0.15 input and $0.60 output per million.
A request with 1,000 input tokens and 500 output tokens on GPT-4o costs:
- Input: 1,000 / 1,000,000 x $2.50 = $0.0025
- Output: 500 / 1,000,000 x $10.00 = $0.005
- Total: $0.0075
That's less than a penny. But multiply by 50,000 requests per day, and you're looking at $375 daily — over $11,000 per month. Use our Cost Calculator to run these numbers for your specific workload.
Does the programming language in your prompt affect token count?
Yes. Different programming languages tokenize at different efficiencies because tokenizers were trained primarily on English text and common code patterns.
Python tends to tokenize relatively well because it's common in training data. Verbose languages like Java use more tokens for the same logic due to longer keywords and boilerplate. Minified JavaScript is surprisingly token-efficient.
If you're including code samples in your prompts — for code review, debugging, or generation tasks — the language choice can swing your token count by 20-30%. Stripping comments and unnecessary whitespace from code samples before sending them as context can save meaningful tokens.
What's the best workflow for managing token costs?
Start by measuring. You can't optimize what you don't track.
- Count tokens before sending — use the Token Counter during development to understand your baseline
- Track per-request costs — monitor every API call's input and output tokens with automated cost tracking
- Set budget alerts — know before you hit your limit, not after (budget alerts guide)
- Optimize prompts — once you see where tokens go, trim the waste
- Pick the right model — don't use GPT-4o for tasks that GPT-4o-mini handles just as well (pricing guide)
The teams that control their LLM costs aren't the ones spending the least. They're the ones who know exactly what they're spending and why.
Frequently Asked Questions
How many tokens is 1,000 words?
Approximately 750 tokens for standard English prose. Technical content with code or specialized terminology runs higher — closer to 800-900 tokens per 1,000 words. JSON-heavy content can hit 1,200+ tokens for the same word count due to structural characters consuming extra tokens.
Do system prompts count toward my token bill?
Yes, and they count on every single request. A 400-token system prompt sent across 1,000 API calls costs you 400,000 input tokens. OpenAI and Anthropic offer prompt caching that discounts repeated prefixes by 50-90%, which helps if your system prompt stays constant across requests.
Why does the same text show different token counts on different models?
Each model family uses its own tokenizer with a different vocabulary. GPT-4o uses o200k_base with ~200K vocabulary entries, while Claude and Gemini use separate BPE implementations. For English text, counts typically vary by 5-10% across providers, but the gap can widen for non-English languages or specialized content.
Are output tokens more expensive than input tokens?
Almost always. OpenAI charges 4x more for output tokens than input on GPT-4o ($10.00 vs $2.50 per million). Anthropic's Claude Sonnet 4 charges 5x more for output ($15.00 vs $3.00). This means a chatty response costs significantly more than a long prompt — controlling max_tokens in your requests directly affects your bill.
All pricing and token counts verified June 2026. Try the LLM Token Counter to count tokens in your own prompts for free.