Budget-first
AI Cost Metering
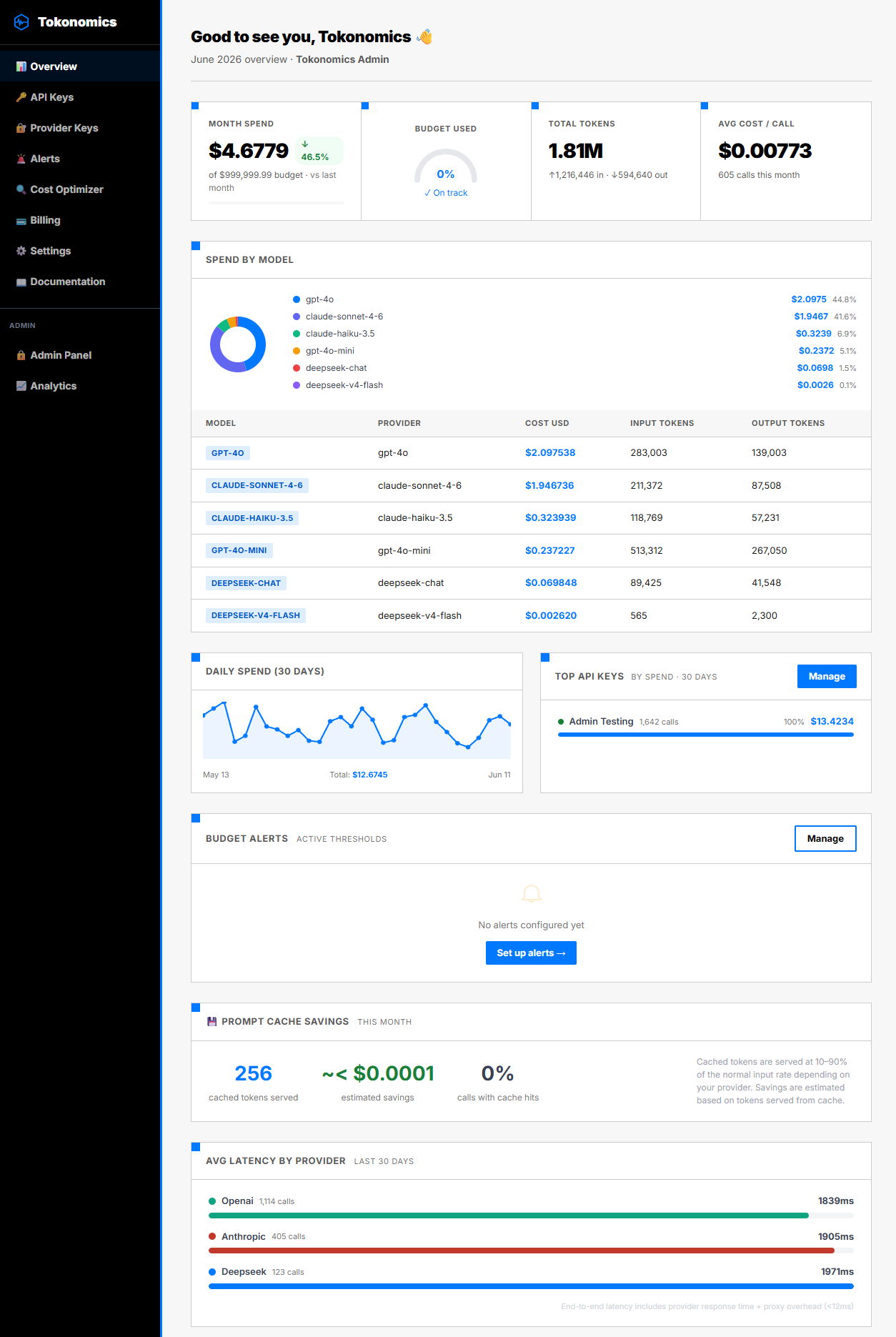
Stop Guessing Your AI API Costs
Tokonomics sits between your app and any LLM provider. Track every token, set budget alerts, and get full cost visibility across all your AI spend.
OpenAI
Anthropic
DeepSeek
Mistral
Gemini
Groq
xAI