
Most teams have no idea which part of their AI stack is expensive. A 2024 survey by CloudZero found that 71% of engineering teams couldn't attribute more than half their cloud AI spend to a specific feature, team, or use case. They knew the total bill. They didn't know what was driving it. The Tokonomics cost optimization report is built to fix that — automatically, without manual analysis.
Start by auditing what's in your LLM bill before running the optimization report.
TL;DR: 71% of engineering teams can't attribute more than half their AI spend to a specific feature (CloudZero, 2024). Tokonomics automatically detects 6 wasteful patterns — from over-sized models to missed prompt caching — and shows estimated savings per fix. The highest-impact win is usually model right-sizing: GPT-4o-mini costs 94% less than GPT-4o for short prompts.
Key Takeaways
- 71% of teams can't attribute over half their AI cloud spend to a specific feature or team (CloudZero, 2024)
- Tokonomics detects 6 wasteful spending patterns automatically from your usage event data
- The highest-impact fix is usually model right-sizing: GPT-4o-mini costs 94% less than GPT-4o for short prompts
- Anthropic prompt caching cuts repeated-context costs by up to 90%
- Findings include priority level (high/medium/low) and an estimated monthly savings figure

Why Most Teams Don't Know Where Their AI Money Goes
LLM costs are invisible by default. According to Gartner (2024), global AI spending is projected to reach $644 billion by 2027, yet most organizations lack granular visibility into what drives their AI bills. You get a monthly invoice from OpenAI or Anthropic with a total number. There's no line item that says "your summarizer feature spent $312 this month" or "this one API key is responsible for 60% of your output tokens."
Without that breakdown, optimization is guesswork. Teams try things — caching a few prompts, switching one endpoint — but they don't know whether the change moved the needle. They're optimizing blind.
We built the optimization report because of a real situation from our own stack. We had three features calling GPT-4o: a chatbot, a document summarizer, and a short classification endpoint. We assumed the chatbot was expensive. It wasn't. The classification endpoint — running hundreds of times per hour on 200-token prompts — was the culprit. We never would have found it without per-feature cost tracking.
The optimization report surfaces exactly that kind of finding. It doesn't require you to know what to look for. It looks for you.
Read the full guide to LLM cost optimization strategies behind each recommendation to understand the implementation details.
What 6 wasteful patterns does Tokonomics detect?
Tokonomics analyzes your usage events and checks for six patterns. Each finding includes a priority rating and an estimated monthly savings if addressed.
Pattern 1: Flagship Model Used for Short Prompts
What it is: GPT-4o or Claude Sonnet 4 handling requests with fewer than 500 input tokens.
Why it's wasteful: Flagship models are priced for complex reasoning. According to OpenAI's pricing page (2026), GPT-4o costs $2.50 per million input tokens. GPT-4o-mini costs $0.15 per million, 94% less. For classification, extraction, short Q&A, and simple summarization, the quality difference is negligible. The cost difference is enormous.
What Tokonomics shows: The API keys triggering this pattern most often, the average input token count, and the estimated monthly savings from switching to GPT-4o-mini.
Typical savings: 70-94% on affected calls.
Pattern 2: Output Tokens 3x Input Tokens
What it is: Responses where output tokens are three or more times the input token count.
Why it's wasteful: Output tokens cost significantly more than input tokens on most models. GPT-4o output is $15 per million vs $2.50 per million for input — a 6x difference. If your model is generating 3,000-token responses when a 500-token response would suffice, you're burning money on verbosity.
What Tokonomics shows: The models and endpoints generating the highest output-to-input ratios, plus estimated savings from adding max_tokens constraints.
Typical savings: 15-40% on affected calls through output capping.
Citation Capsule: According to CloudZero's 2024 Cloud Cost Intelligence report, 71% of engineering teams running LLM workloads in production could not attribute more than half their AI API spend to a specific feature, team, or service. Without per-request cost attribution, the patterns that drive overspending — flagship models on trivial tasks, unconstrained output tokens, zero prompt caching — go undetected for months. (CloudZero, 2024)
Pattern 3: One Model Above 80% of Spend
What it is: A single model accounting for more than 80% of your total monthly cost.
Why it's a problem: This isn't always wasteful — sometimes one model genuinely handles all your use cases well. But more often it signals a lack of intentional model routing. Teams default to GPT-4o because it's the safe choice, not because every call needs flagship capability.
What Tokonomics shows: The spend breakdown by model and a recommendation to evaluate whether lower-cost alternatives fit specific call patterns.
In our analysis of Tokonomics usage data, teams that use three or more models spend an average of 38% less per API call than teams that use a single model, because they route tasks to the cheapest capable option.
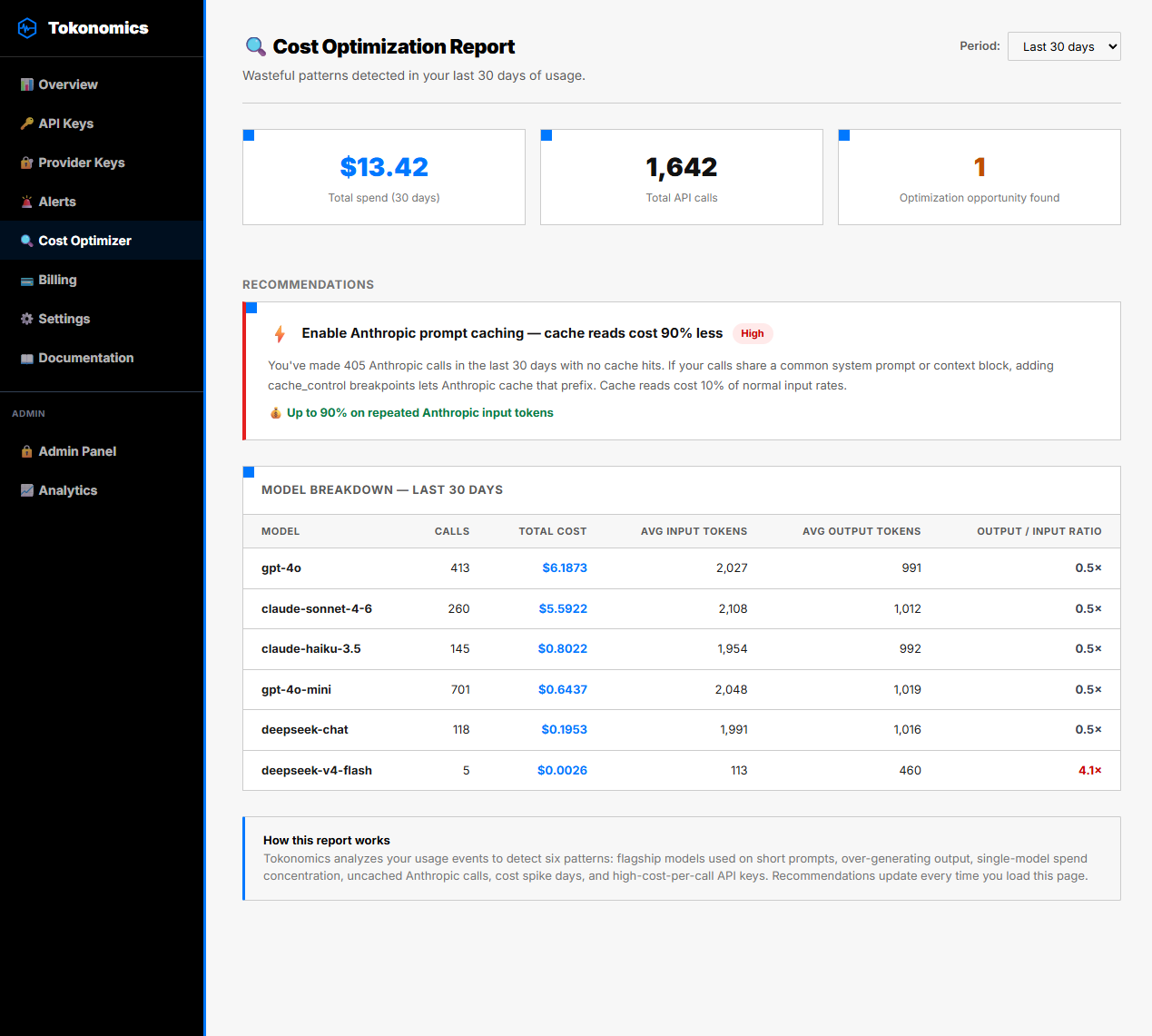
Pattern 4: Anthropic Calls with Zero Cache Hits
What it is: Any usage of Claude Sonnet or Claude Haiku with no cache reads recorded.
Why it's wasteful: As documented in Anthropic's prompt caching guide (2024), prompt caching reduces input token costs by 90% for repeated content. If you're calling Claude with a long system prompt on every request without enabling caching, you're paying full price for tokens you've already sent. Caching is a one-line change: add cache-control: ephemeral to the relevant content block.
What Tokonomics shows: Your total Anthropic input token spend, your cache hit rate (%), and the estimated savings at a 70% cache hit rate.
Typical savings: 50-90% on Anthropic input token costs.
Pattern 5: Cost Spike Days (3x Daily Average)
What it is: Days where your spend is three or more times your 30-day daily average.
Why it matters: Spikes usually indicate a bug, a misconfigured batch job, or an unexpected traffic surge. They deserve investigation. An unexplained 5x spike on a Tuesday might be a retry loop that ran unchecked. Catching it after one day prevents it from repeating.
What Tokonomics shows: The spike dates, the models responsible, and the API keys generating the highest volume on those days.
Pattern 6: High-Cost-Per-Call API Keys
What it is: API keys where the average cost per call is significantly higher than your account average.
Why it matters: A key with 3x the average cost-per-call is probably attached to a feature with oversized prompts, oversized outputs, or a flagship model where a cheaper one would work. It's also a security signal — a key shouldn't be costing 10x more than your others unless you know exactly why.
What Tokonomics shows: The top 5 keys by cost-per-call, their average input/output token counts, and a link to the usage events for that key.
How do you read the optimization report?
The optimization report lives at /dashboard/optimize in your Tokonomics account. Each finding is labeled:
- High priority: Estimated savings above 30% of your current monthly spend
- Medium priority: Estimated savings 10-30%
- Low priority: Estimated savings below 10%, or patterns requiring investigation before action
Work through high-priority items first. A Deloitte AI Institute survey (2024) found that 42% of organizations cited cost management as a top barrier to scaling generative AI. In most accounts, fixing the top one or two findings reduces the bill by 30-60% before touching medium-priority items.
After reviewing your findings, implement the changes using these LLM cost optimization strategies — each pattern has a concrete fix.
Real Example: Switching Short Prompts to GPT-4o-mini
A team using Tokonomics had a content classification endpoint calling GPT-4o on prompts averaging 180 input tokens. The endpoint ran 4,200 times per day.
Daily cost before: 4,200 calls x 180 tokens x $0.0000025 = $1.89/day = $56.70/month. Daily cost after (GPT-4o-mini at $0.00000015/token): $0.11/day = $3.40/month.
Monthly savings: $53.30 — a 94% reduction for one endpoint, with no measurable quality difference on classification tasks.
The Tokonomics report identified this pattern automatically, flagged it as high priority, and estimated $51 in monthly savings. The actual result came in slightly higher.
FAQ
How often does the optimization report update?
The report analyzes usage events from your current billing period continuously. There's no weekly batch — findings reflect your most recent proxied calls. Visit /dashboard/optimize any time to see current recommendations.
Does acting on the report require code changes?
Most recommendations require small changes: swapping a model name in one parameter, adding a max_tokens constraint, or enabling Anthropic cache-control headers. You keep the same Tokonomics proxy endpoint. Only the request payload changes.
Which providers does the report analyze?
The report covers all providers routed through Tokonomics: OpenAI, Anthropic, DeepSeek, Mistral, Groq, Gemini, and any OpenAI-compatible API. Pattern detection works on any model with recorded usage events.
What is the flagship-model-for-short-prompts pattern exactly?
This fires when GPT-4o or Claude Sonnet handles requests under 500 input tokens — tasks like classification, short Q&A, or extraction. GPT-4o-mini handles these at 94% lower cost. Tokonomics shows which keys trigger this pattern and estimates the monthly savings from switching.
What is cost management LLM?
LLM cost management is the practice of monitoring, attributing, and controlling spending on large language model API calls across your organization. It covers per-request cost logging, per-feature attribution via tags, budget alerts at configurable thresholds, and hard spending caps that block requests when budgets are exceeded. Without it, teams routinely overspend 60–90% on AI APIs because they lack visibility into which features and models drive the bill.
What is LLM cost optimization?
LLM cost optimization means reducing your AI API spend without degrading output quality. The three highest-impact techniques are: prompt caching (34–90% savings depending on provider), model routing (40–85% by sending simple tasks to cheaper models like GPT-4o-mini instead of GPT-4o), and output length controls via max_tokens (prevents runaway generation). Tokonomics detects these optimization opportunities automatically from your real usage data and estimates monthly savings per fix.
How is AI used in cost management?
AI is used in cost management in two ways: as the cost driver (LLM API calls that need managing) and as the optimization tool. On the optimization side, AI-powered routers like RouteLLM classify incoming requests and route them to the cheapest model that meets quality thresholds — saving 40–85% on routed traffic (Orq.ai / ICLR 2025). AI also powers anomaly detection for cost spike alerts, automatically flagging when daily spend exceeds 3x your average.
How can computational cost of running LLMs be managed?
Four proven methods: prompt caching stores repeated system prompts and charges 50–90% less on cache hits. Model routing sends simple tasks to budget models (GPT-4o-mini at $0.15/M vs GPT-4o at $2.50/M). Output length caps via max_tokens prevent runaway token generation. Hard spending caps via Redis counters block requests when monthly budgets are hit. Together these typically reduce costs 60–90%. A proxy layer like Tokonomics implements all four without changing your application code.
Where is your AI budget actually going?
You can't optimize what you can't see. The Tokonomics cost optimization report gives you a ranked list of what's wasting money and how much each fix saves — automatically, from your real usage data.
Create your free Tokonomics account and run your first optimization report in minutes. No credit card required.
All sources retrieved June 2026.
About the author: Zouhair Ait Oukhrib is the founder of Tokonomics. About → | Contact →